DeepSeek-V2.5: A New Open-Source Model Combining General and Coding Capabilities
We’ve officially launched DeepSeek-V2.5 – a powerful combination of DeepSeek-V2-0628 and DeepSeek-Coder-V2-0724! This new version not only retains the general conversational capabilities of the Chat model and the robust code processing power of the Coder model but also better aligns with human preferences. Additionally, DeepSeek-V2.5 has seen significant improvements in tasks such as writing and instruction-following. The model is now available on both the web and API, with backward-compatible API endpoints. Users can access the new model via deepseek-coder or deepseek-chat. Features like Function Calling, FIM completion, and JSON output remain unchanged. The all-in-one DeepSeek-V2.5 offers a more streamlined, intelligent, and efficient user experience.
Version History
DeepSeek has consistently focused on model refinement and optimization. In June, we upgraded DeepSeek-V2-Chat by replacing its base model with the Coder-V2-base, significantly enhancing its code generation and reasoning capabilities. This led to the release of DeepSeek-V2-Chat-0628. Shortly after, DeepSeek-Coder-V2-0724 was launched, featuring improved general capabilities through alignment optimization. Ultimately, we successfully merged the Chat and Coder models to create the new DeepSeek-V2.5.
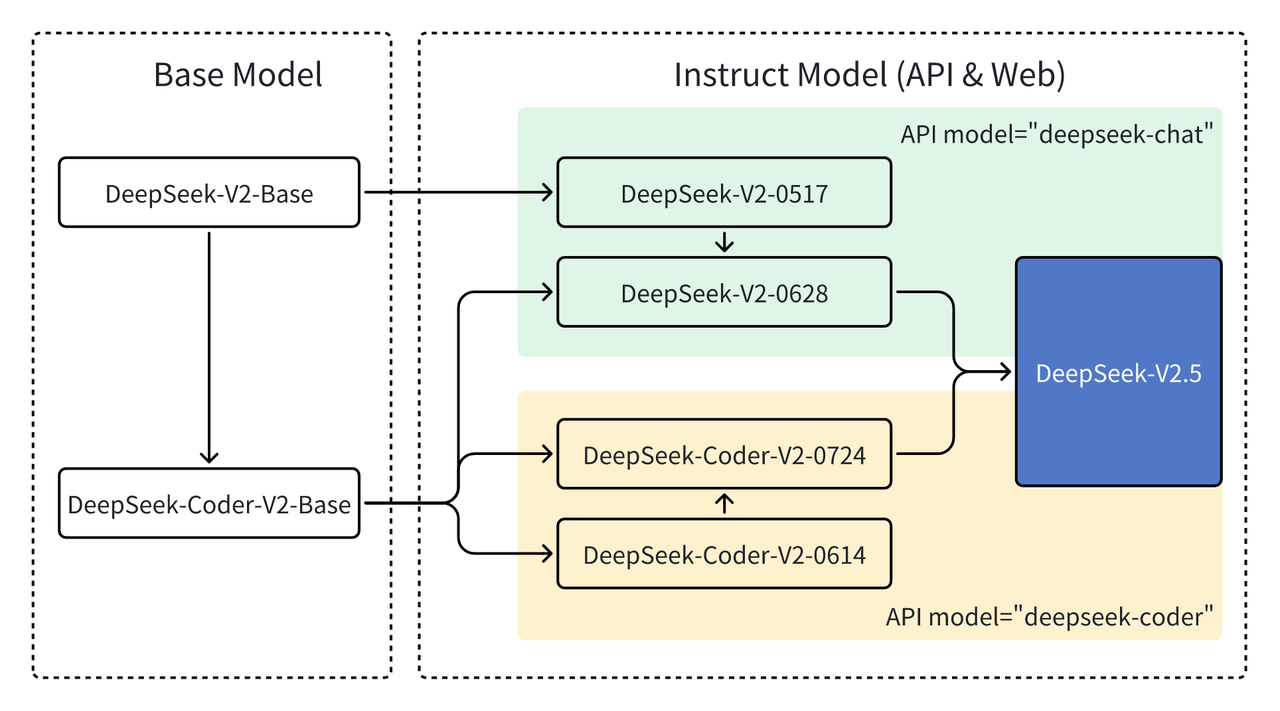
Note: Due to significant updates in this version, if performance drops in certain cases, we recommend adjusting the system prompt and temperature settings for the best results!
General Capabilities
- General Capability Evaluation
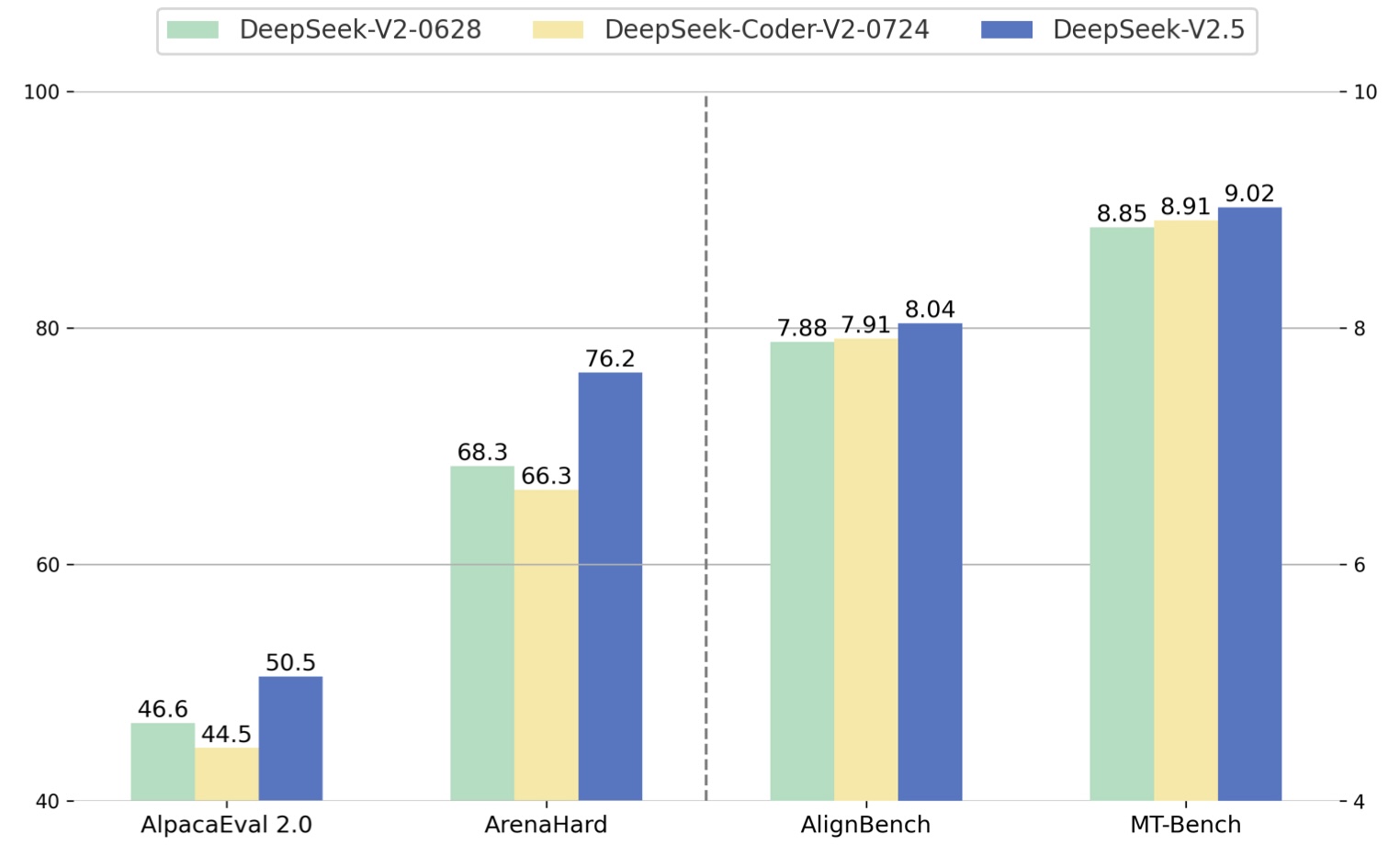
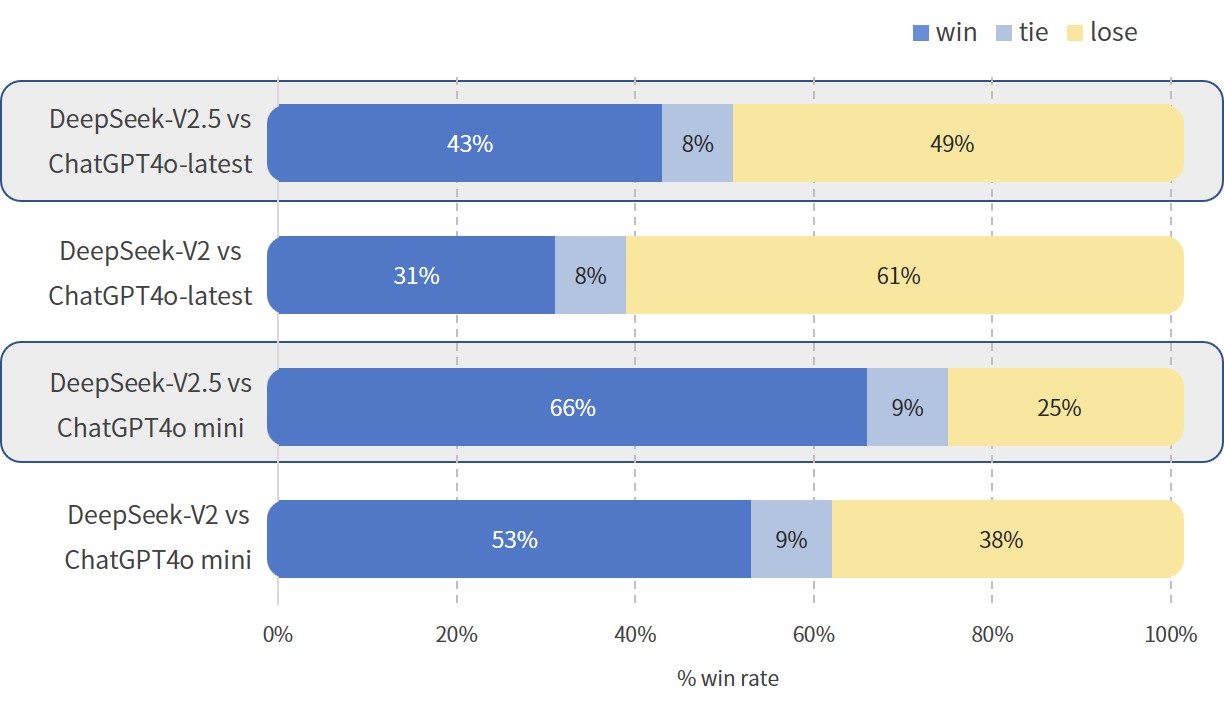
We assessed DeepSeek-V2.5 using industry-standard test sets. DeepSeek-V2.5 outperforms both DeepSeek-V2-0628 and DeepSeek-Coder-V2-0724 on most benchmarks. In our internal Chinese evaluations, DeepSeek-V2.5 shows a significant improvement in win rates against GPT-4o mini and ChatGPT-4o-latest (judged by GPT-4o) compared to DeepSeek-V2-0628, especially in tasks like content creation and Q&A, enhancing the overall user experience.
- Safety Evaluation
Balancing safety and helpfulness has been a key focus during our iterative development. In DeepSeek-V2.5, we have more clearly defined the boundaries of model safety, strengthening its resistance to jailbreak attacks while reducing the overgeneralization of safety policies to normal queries.
| Model | Overall Safety Score (higher is better)* | Safety Spillover Rate (lower is better)** |
|---|---|---|
| DeepSeek-V2-0628 | 74.4% | 11.3% |
| DeepSeek-V2.5 | 82.6% | 4.6% |
* Scores based on internal test sets: higher scores indicates greater overall safety.
** Scores based on internal test sets:lower percentages indicate less impact of safety measures on normal queries.
Code Capabilities
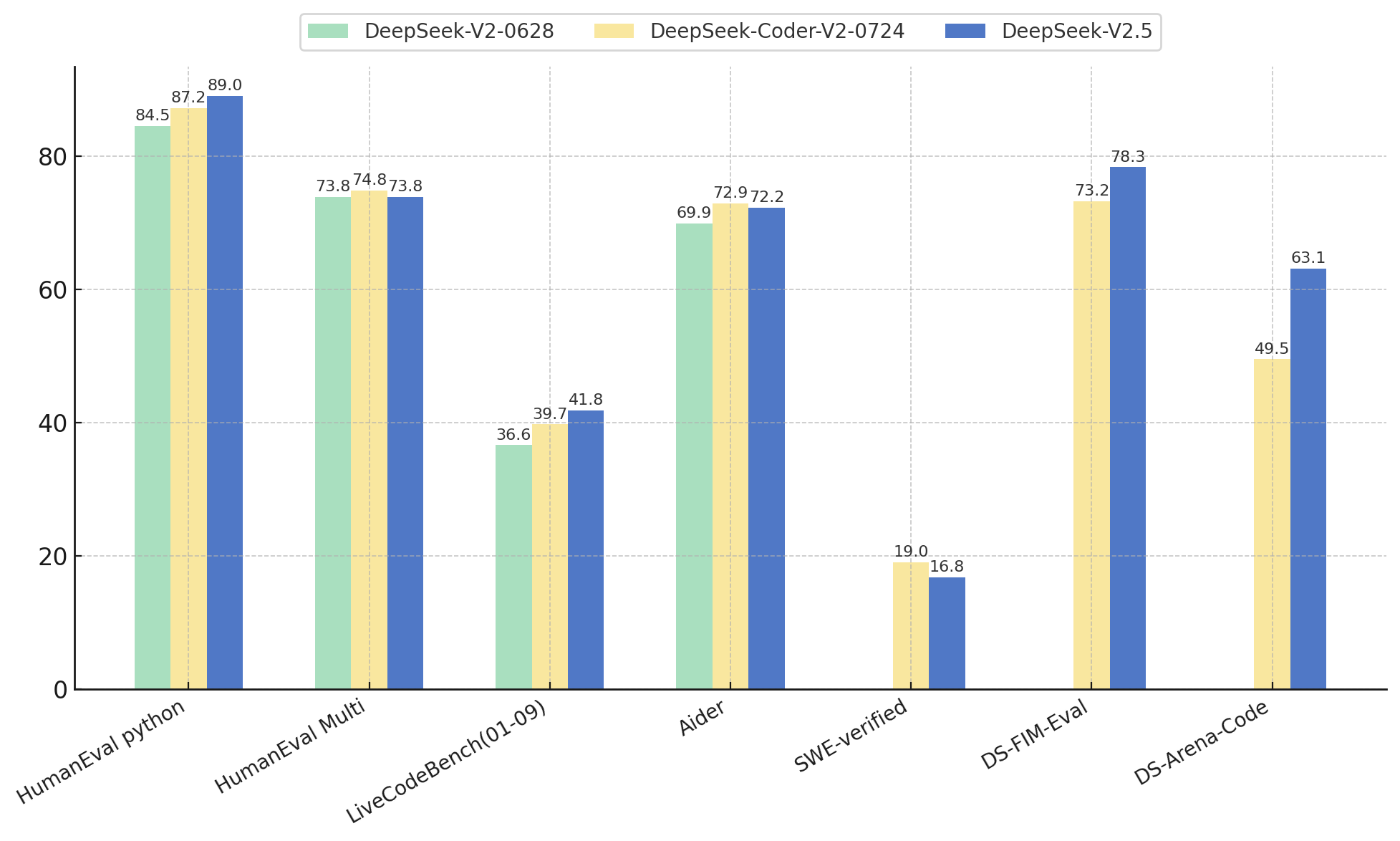
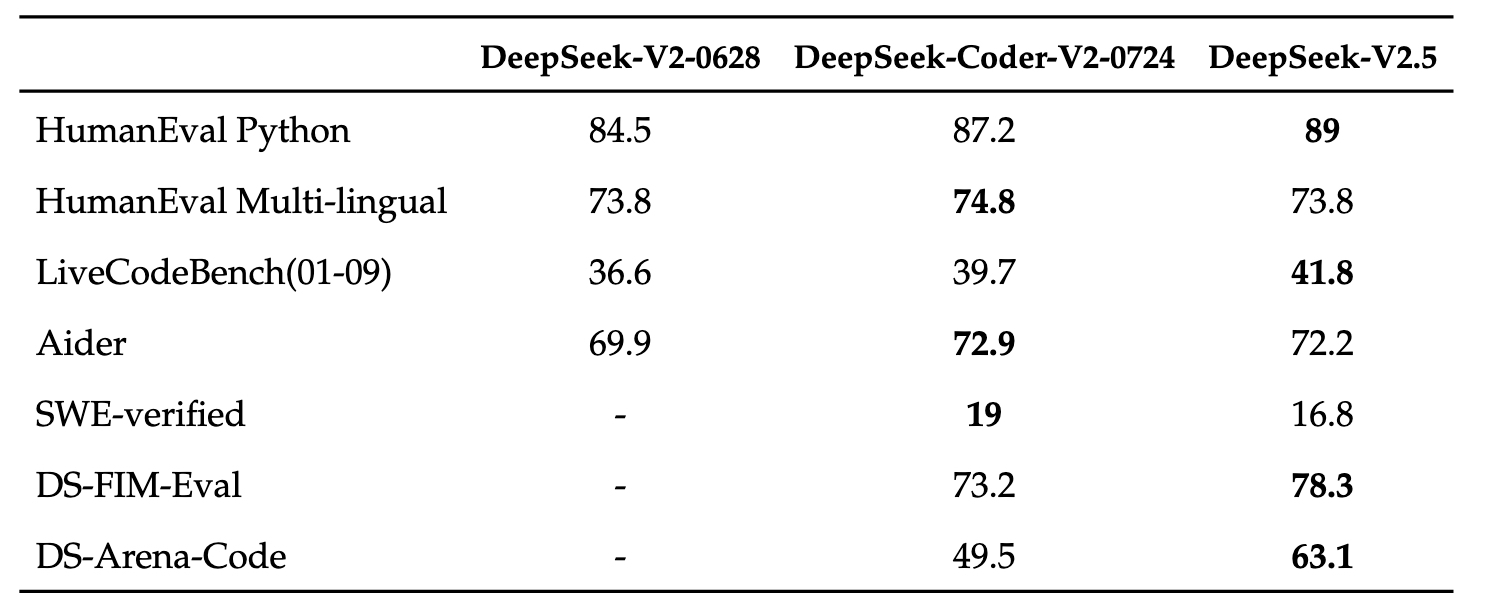
In the coding domain, DeepSeek-V2.5 retains the powerful code capabilities of DeepSeek-Coder-V2-0724. It demonstrated notable improvements in the HumanEval Python and LiveCodeBench (Jan 2024 - Sep 2024) tests. While DeepSeek-Coder-V2-0724 slightly outperformed in HumanEval Multilingual and Aider tests, both versions performed relatively low in the SWE-verified test, indicating areas for further improvement. Moreover, in the FIM completion task, the DS-FIM-Eval internal test set showed a 5.1% improvement, enhancing the plugin completion experience. DeepSeek-V2.5 has also been optimized for common coding scenarios to improve user experience. In the DS-Arena-Code internal subjective evaluation, DeepSeek-V2.5 achieved a significant win rate increase against competitors, with GPT-4o serving as the judge.
Open-Source
DeepSeek-V2.5 is now open-source on HuggingFace! Check it out: