DeepSeek API introduces Context Caching on Disk, cutting prices by an order of magnitude
In large language model API usage, a significant portion of user inputs tends to be repetitive. For instance, user prompts often include repeated references, and in multi-turn conversations, previous content is frequently re-entered.
To address this, DeepSeek has implemented Context Caching on Disk technology. This innovative approach caches content that is expected to be reused on a distributed disk array. When duplicate inputs are detected, the repeated parts are retrieved from the cache, bypassing the need for recomputation. This not only reduces service latency but also significantly cuts down on overall usage costs.
For cache hits, DeepSeek charges $0.014 per million tokens, slashing API costs by up to 90%.

How to Use DeepSeek API's Caching Service
The disk caching service is now available for all users, requiring no code or interface changes. The cache service runs automatically, and billing is based on actual cache hits.
Note that only requests with identical prefixes (starting from the 0th token) will be considered duplicates. Partial matches in the middle of the input will not trigger a cache hit.
Here are two classic cache usage scenarios:
1. Multi-turn conversation: The next turn can hit the context cache generated by the previous turn.
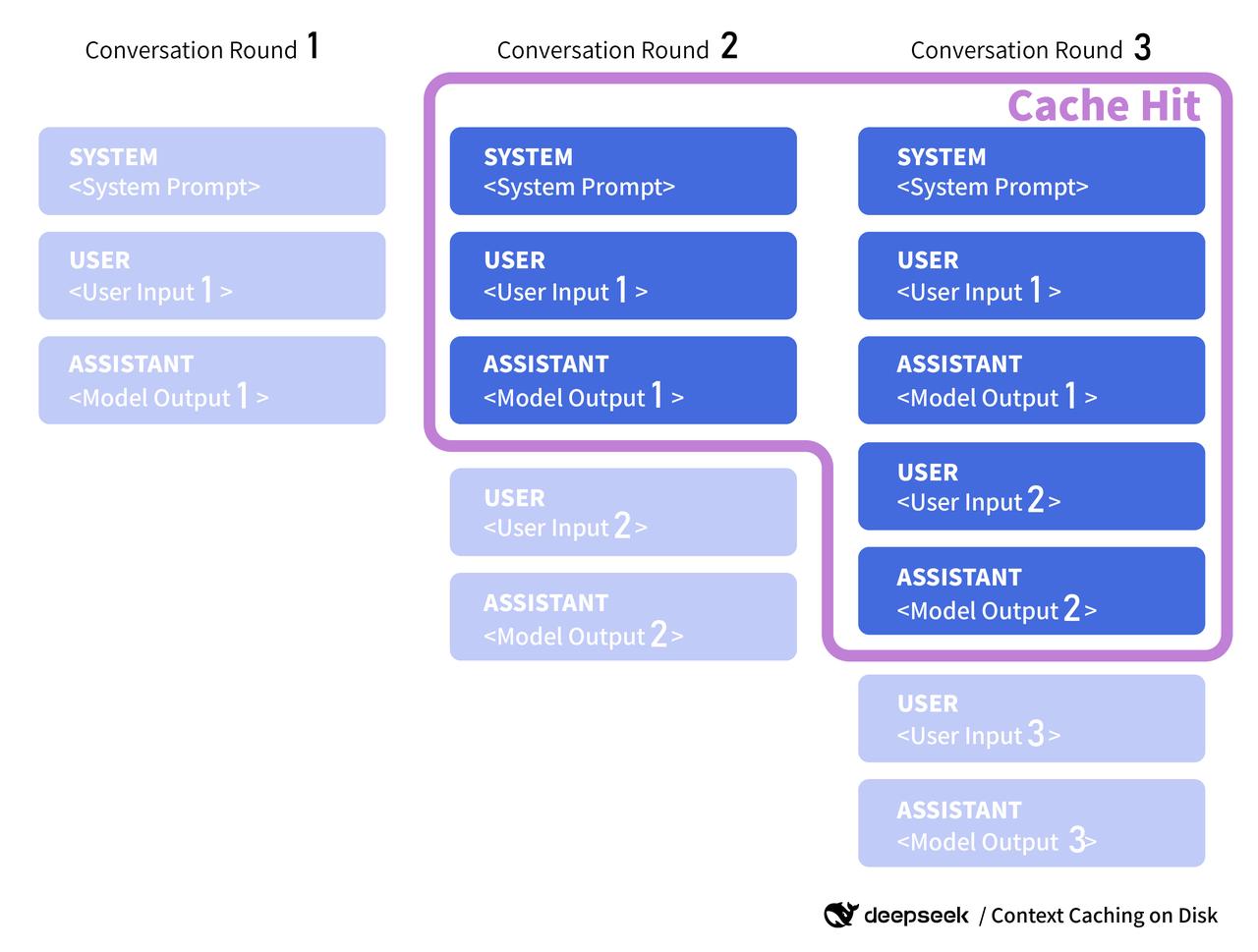
2. Data analysis: Subsequent requests with the same prefix can hit the context cache.
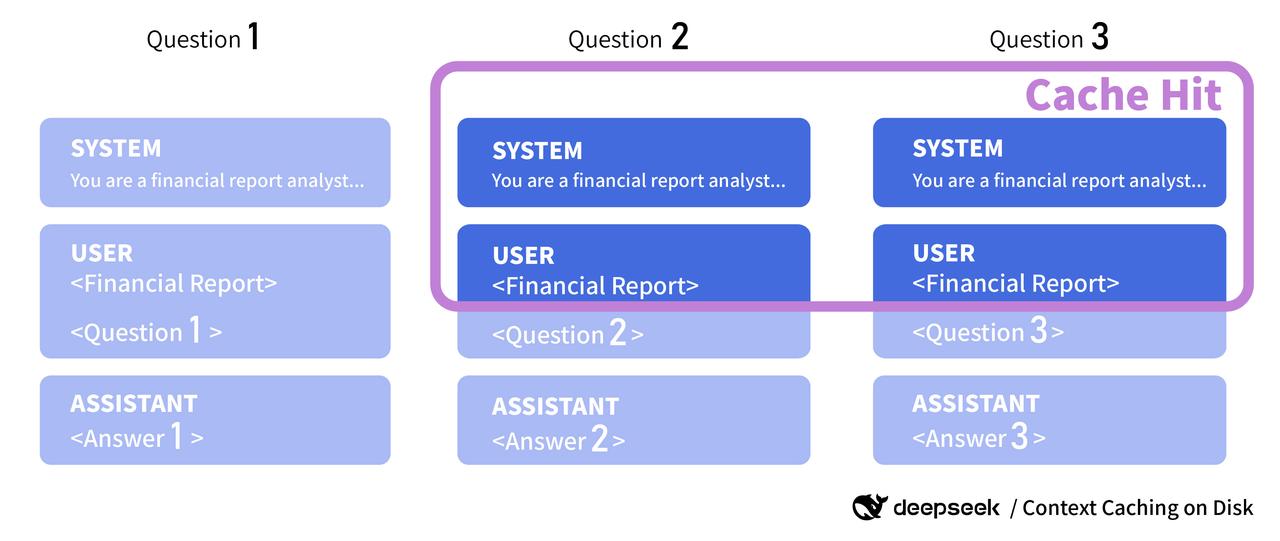
Beneficial Scenarios for Context Caching on Disk:
- Q&A assistants with long preset prompts
- Role-play with extensive character settings and multi-turn conversations
- Data analysis with recurring queries on the same documents/files
- Code analysis and debugging with repeated repository references
- Improve model output performance through Few-shot learning.
- ...
For more detailed instructions, please refer to the guide Use Context Caching.
Monitoring Cache Hits
Two new fields in the API response's usage section help users monitor cache performance:
- prompt_cache_hit_tokens:Number of tokens from the input that were served from the cache ($0.014 per million tokens)
- prompt_cache_miss_tokens: Number of tokens from the input that were not served from the cache ($0.14 per million tokens)
Reducing Latency
First token latency will be significantly reduced in requests with long, repetitive inputs.
For a 128K prompt with high reference, the first token latency is cut from 13s to just 500ms.
Lowering Costs
Users can save up to 90% on costs with optimization for cache characteristics.
Even without any optimization, historical data shows that users save over 50% on average.
The service has no additional fees beyond the $0.014 per million tokens for cache hits, and storage usage for the cache is free.
Security Concerns
The cache system is designed with robust security strategy.
Each user's cache is isolated and logically invisible to others, ensuring data privacy and security.
Unused cache entries are automatically cleared after a period, ensuring they are not retained or repurposed.
Why DeepSeek Leads with Disk Caching
Based on publicly available information, DeepSeek appears to be the first large language model provider globally to implement extensive disk caching in API services.
This is made possible by the MLA architecture in DeepSeek V2, which enhances model performance while significantly reducing the size of the context KV cache, enabling efficient storage on low-cost disks.
DeepSeek API’s Concurrency and Rate Limits
The DeepSeek API is designed to handle up to 1 trillion tokens per day, with no limits on concurrency or rate, ensuring high-quality service for all users. Feel free to scale up your parallelism.
The cache system uses 64 tokens as a storage unit; content less than 64 tokens will not be cached.
The cache system does not guarantee 100% cache hits.
Unused cache entries are automatically cleared, typically within a few hours to days.